Why Move from a Database to a Data Warehouse for Analytics?

Core Reasoning
1. Specialized Architectural Design for Analytical Workloads
Operational databases (e.g., MongoDB, MySQL, PostgreSQL) are primarily row-oriented systems optimized for transactional workloads: frequent inserts, updates, and low-latency lookups on relatively small portions of data (think 100s of GBs at max). Their indexing strategies, lock management, and storage engines are tuned for OLTP (Online Transaction Processing) patterns.
Data warehouses (e.g., Snowflake, BigQuery, ClickHouse) are purpose-built for large-scale analytical queries (OLAP). They use columnar storage, extensive compression, vectorized execution, and sophisticated cost-based optimizers to scan billions of rows quickly.
Read about why Datazip chose Clickhouse to provide a managed data warehouse solution
This architectural distinction is not marketing fluff; benchmark tests regularly show columnar engines outperforming row-stores by orders of magnitude for aggregation-heavy queries.
For example, ClickHouse benchmarks by Altinity and community tests show sub-second analytics on trillions of rows—something not feasible with typical row-store databases under the same conditions.
ClickHouse vs Spark powered MySQL query running time comparison [partial screenshot for brevity]
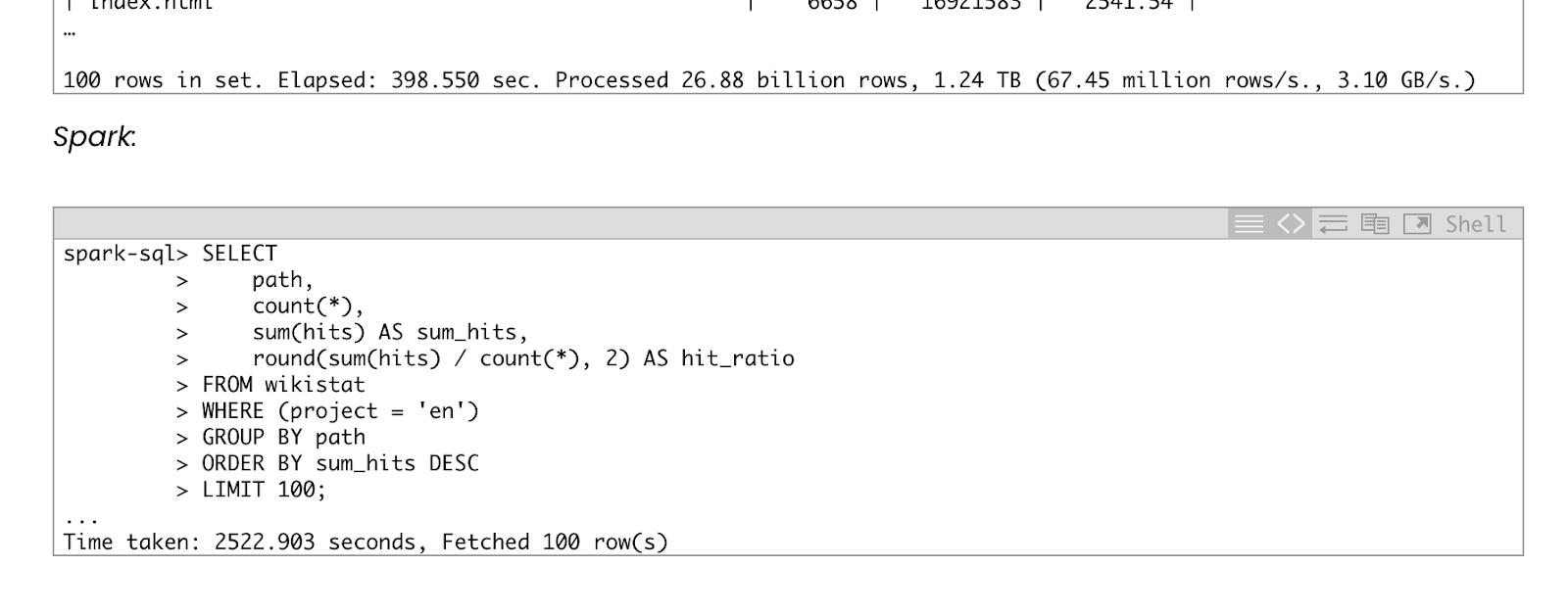
See full benchmark here - Source
2. Enhanced Query Performance and Concurrency
Analytical queries often need to scan wide swaths of historical data, join multiple large datasets, and apply complex calculations. Row-based OLTP databases degrade substantially as data volumes reach tens or hundreds of gigabytes.
In contrast, modern warehouses employ massive parallel processing (MPP) architectures. Services like Snowflake, BigQuery, and Azure Synapse distribute queries across multiple nodes, dynamically scaling resources to handle concurrent analytical workloads.
BigQuery’s internal papers and user case studies confirm that complex queries on terabytes of data complete in seconds or minutes without manual tuning—a performance profile operational DBs cannot match in a cost-effective manner.
3. Separation of Compute and Storage
Leading data warehouses separate compute from storage,(like how we did with openengine) allowing organizations to scale CPU and memory resources independently of data volume. Snowflake popularized this model, and most cloud warehouses now follow it.
This decoupling means that analysts can run high-concurrency, resource-intensive queries without impacting operational systems. Trying to achieve this on an OLTP database typically results in resource contention, transactional slowdowns, and the need for continuous hardware upgrades.
4. Advanced Analytical Features and SQL Extensions
Data warehouses offer a rich set of analytical functions, window functions, and statistical extensions that simplify complex transformations and aggregations.
For example, SQL window functions in Redshift or Snowflake can handle cohort analyses (technique that groups users with shared characteristics and analyzes their behavior over time**)**, time-series computations, and running totals far more elegantly and efficiently than custom pipeline code in a traditional DB.
These features reduce ETL complexity and coding overhead, as confirmed by numerous engineering teams that migrated from hand-rolled ETL jobs on OLTP DBs to declarative SQL transformations in warehouses. Tools like dbt also leverage warehouse capabilities for modular, version-controlled transformations that are harder to manage in operational databases.
5. Stability and SLA Guarantees at Scale
As datasets grow, operational databases face challenges like index bloat, lock contention, and replication lag. Analytical queries exacerbate these issues by introducing heavy read loads. Data warehouses, by design, expect and handle large analytical workloads.
Their service-level agreements (SLAs) often guarantee predictable performance at scale. Google’s BigQuery documentation and public SLA statements, for instance, show that the system is built to handle large-scale analytics reliably.
Operational DBs typically require elaborate partitioning, caching strategies, and continuous index tuning to approach similar reliability and performance, increasing maintenance overhead and complexity.
6. Ecosystem and Tooling
The modern analytics stack—BI tools, data modeling frameworks, machine learning platforms—assumes the presence of a performant analytical store. Many enterprise-grade BI platforms are optimized to push complex calculations into the warehouse.
Tableau, Looker, and Power BI documentation consistently recommend columnar or MPP (Massively Parallel Processing, Azure SQL Data Warehouse) warehouses to achieve acceptable dashboard refresh times at scale. Attempting similar workloads directly on an OLTP DB leads to slow dashboards and frustrated analysts.
7. Real-World Case Studies
-
Netflix and Uber: Both have publicly discussed their use of columnar data stores (like Presto/Trino on top of S3 data, or ClickHouse for real-time analytics) to achieve sub-second queries over petabytes of data. Attempting the same scale on a row-oriented OLTP system is cost-prohibitive and operationally fragile.
-
Etsy’s Migration Off MongoDB for Analytics: Etsy engineers have written about moving critical analytical workloads off MongoDB and into databases better suited for analytics. MongoDB’s aggregation framework became unwieldy, and performance lagged once their data volumes grew.
-
Advertising and Marketing Analytics: Companies analyzing clickstream ( user's interactions record with a website or app) data (often billions of events per day) rely on warehouses like BigQuery or columnar DBs like ClickHouse. Benchmarks show that these systems can return analytical queries in seconds, whereas a traditional database would struggle or require significant manual sharding and tuning.
Below is a tabular comparison between the two approaches.
| Aspect | Traditional Operational DB (e.g., MongoDB, MySQL) | Dedicated Data Warehouse (e.g., Snowflake, BigQuery, ClickHouse) |
|---|---|---|
| Primary Design Goal | Optimized for transactional reads/writes and real-time operations | Optimized for complex aggregations, large-scale analytical queries, and reporting |
| Data Storage Format | Usually row-oriented (documents or rows) | Columnar or hybrid, enabling efficient compression and scans |
| Query Complexity | Efficient for point lookups and small-scale joins | Excels at multi-table joins, window functions, and large-scale, multi-step aggregations |
| Scaling Method | Often tied to hardware; scaling up increases complexity and cost | MPP (Massively Parallel Processing) and separated compute/storage for easy scaling |
| Typical Latency Expectations | Sub-millisecond to millisecond latency for small queries | Seconds to minutes, but handles huge datasets with predictable performance |
| Data Volume Handling | Ideal for GB-level data; performance drops off with large analytical loads | Built to handle TB-PB of data without a severe performance hit. |
| Maintenance & Tuning | Requires indexing, caching, and careful schema design as data grows. | Minimal tuning needed; built-in optimizations handle variable workloads well |
| Core Use Cases | High-volume web apps, user-facing queries, real-time order entry systems | BI dashboards, extensive historical trend analysis, complex event aggregation |
| Ideal Scenarios | Low-latency CRUD operations, session management, product catalogs | Weekly/monthly business reports, customer 360 analytics, predictive modeling |
| Integration with BI Tools | Often limited; dashboards may lag due to raw scans | Seamless; BI tools push complex logic to warehouse, returning fast aggregated results |
Read: How to deal with polymorphic data (Changing data-types)
7 Key differences between Databases vs Data Warehouses: A Glance
-
OLTP vs. OLAP Focus
Databases excel at handling Online Transaction Processing (OLTP), designed for frequent, simple transactions such as order processing, user authentication, or inventory management. Data warehouses, on the other hand, are built for Online Analytical Processing (OLAP), which involves complex queries to uncover business insights, trends, and patterns.
-
Concurrency and User Load
Operational databases are designed to handle thousands of concurrent users performing small transactions. Data warehouses are optimized for a smaller group of users, such as data analysts or BI tools, running complex analytical queries.
-
Transaction Granularity
Databases are ideal for managing small, granular transactions (e.g., updating a single row or processing one user action). Data warehouses handle larger, aggregated queries that combine data from multiple sources for deeper insights.
-
Availability Requirements
Databases are mission-critical for daily operations and require near-zero downtime since outages can disrupt business processes. Data warehouses, while important, can tolerate occasional planned downtime for updates or maintenance without significant impact on ROI.
-
Query Optimization
Databases are optimized for fast CRUD (Create, Read, Update, Delete) operations, ensuring sub-millisecond performance for single-record lookups (important). Data warehouses prioritize batch processing, aggregation, and read-heavy operations over write efficiency, allowing them to process complex multi-step queries over vast datasets.
Read More: How to Query Semi-Structured JSON Data in Snowflake?
-
Schema Design
Databases use normalized schemas to minimize redundancy and maximize storage efficiency. Data warehouses, by contrast, employ denormalized schemas (like star or snowflake schema designs), trading storage efficiency for faster read performance, particularly during analytical queries.
-
Historical vs. Real-Time Data
Databases are designed to store the most current data, making them unsuitable for long-term trend analysis or historical queries. Data warehouses aggregate and retain historical data over months or years, enabling trend analysis, forecasting, and longitudinal studies.
Conclusion
Operational databases are critical for real-time, transaction-focused workloads but fail to deliver efficient large-scale analytics due to their row-oriented storage, limited parallelization, and less advanced query optimization strategies. Data warehouses, engineered for OLAP, offer columnar compression, distributed execution, and advanced analytical SQL capabilities that enable sub-second queries over massive datasets.
The move from DB to a dedicated data warehouse is not a matter of preference— it’s driven by architectural fit, proven performance improvements, reduced maintenance complexity, and the ability to handle ever-growing volumes of data and concurrent analytical workloads. Evidence from benchmarks, engineering blogs, and large-scale user case studies consistently supports this shift.